How Pyxis closes the gap to Orbitrap-grade quant
Your team's quant data quality has long been defined by the instruments you have access to. Groups with research-grade instruments like the Orbitrap have had reliable, quantitative answers, while groups on lower-resolution benchtops have had to settle for directional reads or narrower targeted panels.
Our latest version of Pyxis Quant closes this gap significantly. We trained our model on the largest concentration-annotated LC-MS dataset to date, spanning Orbitraps (OE120, OE480, QE-HF, ID-X, Fusion Lumos) and the Waters BioAccord.
On the lower-resolution platforms, Pyxis now delivers Orbitrap-grade quant for the abundant analytes that drive bioprocess decisions. Hardware floors still apply, with sensitivity and near-isobar resolution bound to the instrument itself; but, within those floors, the model is no longer what holds lower-resolution instruments back.
A bioprocess case study on the BioAccord
We ran the same CHO spent media samples on a BioAccord and an Orbitrap (OE120) and processed both through the latest version of Pyxis (v1.11). Across 153 analytes over a 14-day run and two supernatant conditions, BioAccord-Orbitrap agreement tightened 3x, and allowed the BioAccord to capture day-by-day trajectory shape across the panel.
Given that operational decisions in CHO culture depend on trajectory signal, this allows any group with a BioAccord to inform calls on when to feed, when to harvest, whether a culture is diverging from prior batches, and whether amino acid depletion is approaching levels that affect product quality.
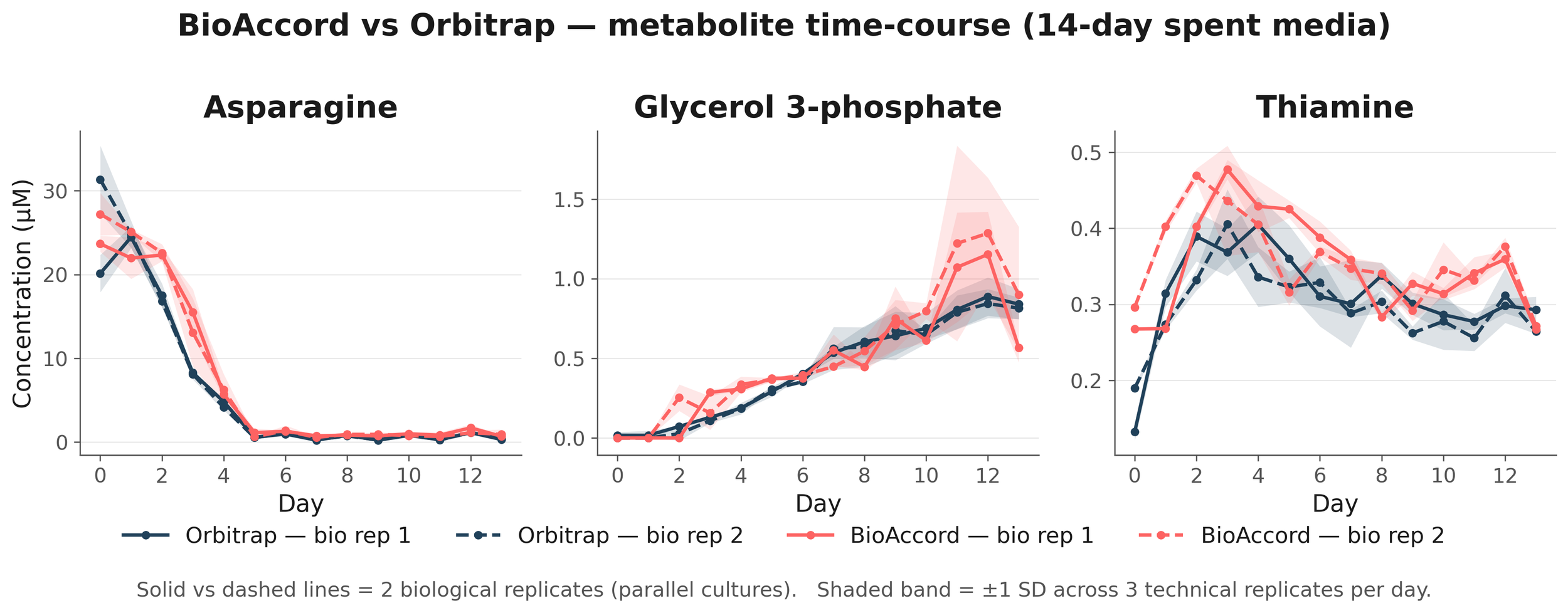
Cross-Instrument Generalization
Our newest Pyxis model version is trained across a diverse set of mass spectrometers, which lets us measure how consistently it quantifies the same chemistry across very different hardware.
On matrix plates run identically on every instrument, it delivers the best cross-instrument consistency of any model version, reducing the cross-benchmark coefficient of variation for endogenous analytes by 8%. False positive rate falls sharply across benchmarks, by more than 50% on our core HILIC benchmark and by 97% on our BioAccord benchmark, while median quantitation error on heavy-labeled standards improved by 13%.
We also achieved consistency gains on the instruments that were previously hardest to quantify, with dilution-normalized consistency on Fusion Lumos improving by 27%.
The fact that consistency improves across such different hardware is the clearest signal that Pyxis is quantifying real chemistry, not memorizing the behavior of one instrument.
Pushing accuracy further with calibration
When an application demands more precision, we find that a single plate of instrument-specific data boosts model performance further.
On an instrument held out of the base model's training (Orbitrap ID-X), a single calibration plate more than doubles the fraction of analytes quantified within 30% of the true value and cuts quantification error by roughly 63% on a held-out plate from that instrument.
The same calibration also helps on biological matrices, where a single plate reduces error by roughly 15%, with further gains as more plates are added. Together, these results point to a fast onboarding path, where any new lab can reach strong quantitation accuracy from a single instrument-specific calibration plate and a single fine-tuning pass, without a large data-collection effort.
Availability
The latest Pyxis Quant model is available to all enterprise customers as the new default HILIC model now, with calibration support for instrument-specific deployments. Reach out to info@matterworks.ai to learn more about this model, and custom deployments, from our team.